|
|
|
| Ce document est disponible en: English Deutsch Francais Turkce |
![[Photo of the Author]](../../common/images2/iznoT2.png)
par Iznogood <iznogood/at/iznogood-factory.org> L´auteur: Je suis sous GNU/Linux depuis un bon moment et actuellement sur une Debian. Malgré des études électronique, je fais surtout du travail de traduction pour la communauté GNU/Linux. Traduit en Français par: Iznogood <iznogood/at/iznogood-factory.org> Sommaire: |
Une chaîne d'outils pour la transformation du papier en HTMLRésumé:
Ou comment convertir un vieux magazine papier en un document html. Je vais
vous expliquer le processus, depuis la numérisation jusqu'à la mise en forme
html.
|
J'ai lu que certaines universités américaines aideront ou permettront à
Google de numériser leur bibliothèque. Je ne suis pas Google et je suis loin
d'avoir une bibliothèque d'université mais je possède quelques vieux numéros
d'une revue d'électronique. Et la qualité du papier n'est pas des meilleures:
les pages commencent à se détacher, le papier devient gris...
J'ai donc décidé de les numériser car, malgré la disparition de la revue il y
a 10 ans, certains (beaucoup) des articles restent actuels! Pour de
l'électronique, 10 ans, c'est le moyen âge. C'est dire la qualité des articles.
Pour commencer, j'ai eu besoin de rentrer les données dans l'ordinateur.
Un scanner est fait pour cela: après avoir vérifié la compatibilité, j'en ai
acheté un, un vieux ScanJet 4300C d'occasion mais pas cher et en navigant
sur internet, j'ai trouvé les informations de configuration.
Sur la Debian, j'ai installé sane, xsane, gocr et gtk-ocr comme d'habitude
avec:
apt-get install sane xsane gocr gtk-ocren tant que root.
sane-find-scannerme l'a confirmé puis je suis allé dans /etc/sane.d/ pour éditer quelques fichiers:
hp niashet j'ai mis le reste en commentaire.
/dev/usb/scanner0 option connect-deviceet j'ai mis le reste en commentaire.
chgrp scanner scanner0et j'ai ajouté iznogood (c'est moi!) comme utilisateur pour me permettre d'utiliser le scanner sans être root:
adduser iznogood scannerUn reboot et c'était réglé!
append="hdb=ide-scsi ignore hdb"puis
lilopour rendre le changement effectif.
/dev/sdc0 /dvdrom iso9660 user, noauto 0 0Puis j'ai changé le groupe de scd0 en cdrom
chgrp cdrom scd0Assez facile.
Pour continuer le processus, j'ai eu besoin de quelques logiciels:
sane, xsane, gimp, gocr, gtk-ocr, un éditeur de texte, de html et de l'espace
sur le disque dur.
sane est l'interface avec le scanner et xsane, son interface graphique.
L'idée était de garder une résolution maximale et d'obtenir un fichier de
50 Mo par page, de la stocker sur le disque dur pour la travailler puis la
stocker sur un DVDROM.
J'ai mis la résolution à 600 dpi, un peu plus de luminosité et j'ai débuté la
conversion. Comme c'est sur une très vieille machine (un PII 350 MHz), cela a
pris du temps mais j'ai obtenu une image précise. Je l'ai sauvegardée au
format libre png.
Pourquoi une telle résolution et un fichier de 50 Mo? Je voulais garder une
résolution maximum pour les archives et pour un traitement numérique ultérieur
(et au prix où sont les DVDROM, je n'allais pas me gêner!).
Avec Gimp, j'ai découpé la page en séparant les images graphiques des images
textes.
Les graphiques ont été sauvegardés en png avec une taille réduite pour rentrer
dans une page html et les images texte n'ont pas été réduits mais changés en
niveaux de gris (Outils, Outils des Couleurs, Seuil et Ok puis Image, Mode,
Niveau de gris) et sauvegardé avec une extension .pcx pour le traitement avec
le logiciel de reconnaissance de caractères.
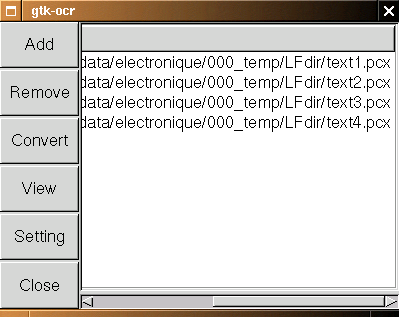
cat *.txt > test.txtJ'ai eu un test.txt et avec un éditeur de texte, j'ai eu besoin d'effectuer quelques ajustements (suppression de quelques caractères non français, correction de mots...).
Je me rappelle toujours un prof de maths, lors que j'étais jeune, qui m'avait
donné cette maxime:
« Pour être fainéant, il faut être intelligent ».
Bien, je vais commencer par être fainéant !!!! ;-)
Il y a des parties du traitement qui ne sont pas facile à automatiser (création de répertoire, numérisation, découpage avec gimp et création de fichiers). Le reste peut être automatisé.
Il existe un tutoriel en anglais absolument fabuleux sur le scripting en bash, ABS (Advanced Bash Scripting Guide) et j'ai trouvé une traduction française!.
Vous pouvez trouver la version anglaise sur www.tldp.org.
Ce guide m'a permis d'écrire un petit programme. Vous avez le script ici:
#!/bin/bash REPERTOIRE=$(pwd) cd $REPERTOIRE mkdir ../ima mv *.png ../ima/ for i in `ls *` do gocr -f UTF8 -i $i -o $i.txt done cd .. mv ima/ $REPERTOIRE cd $REPERTOIRE cat *.txt | sed -e 's/_//g' -e 's/(PICTURE)//g' -e 's/ì/i/g' \ -e 's/í/i/g' -e 's/F/r/g' -e 's/î/i/g' > test.txt
ocr-rppwd donnera le chemin du répertoire au script, puis ima est créé à l'extérieur du répertoire et tous les fichiers .png y sont déplacés. Tous les fichiers .txt sont alors listés, traités avec gocr, concaténés dans test.txt et ont subis quelques changements pour avoir des caractères français.
|
Site Web maintenu par l´équipe d´édition LinuxFocus
© Iznogood "some rights reserved" see linuxfocus.org/license/ http://www.LinuxFocus.org |
Translation information:
|
2005-06-27, generated by lfparser version 2.52